A few days ago, GhostProxies.com came up with an interesting infographic showing some stats on Internet and social-web fakery. 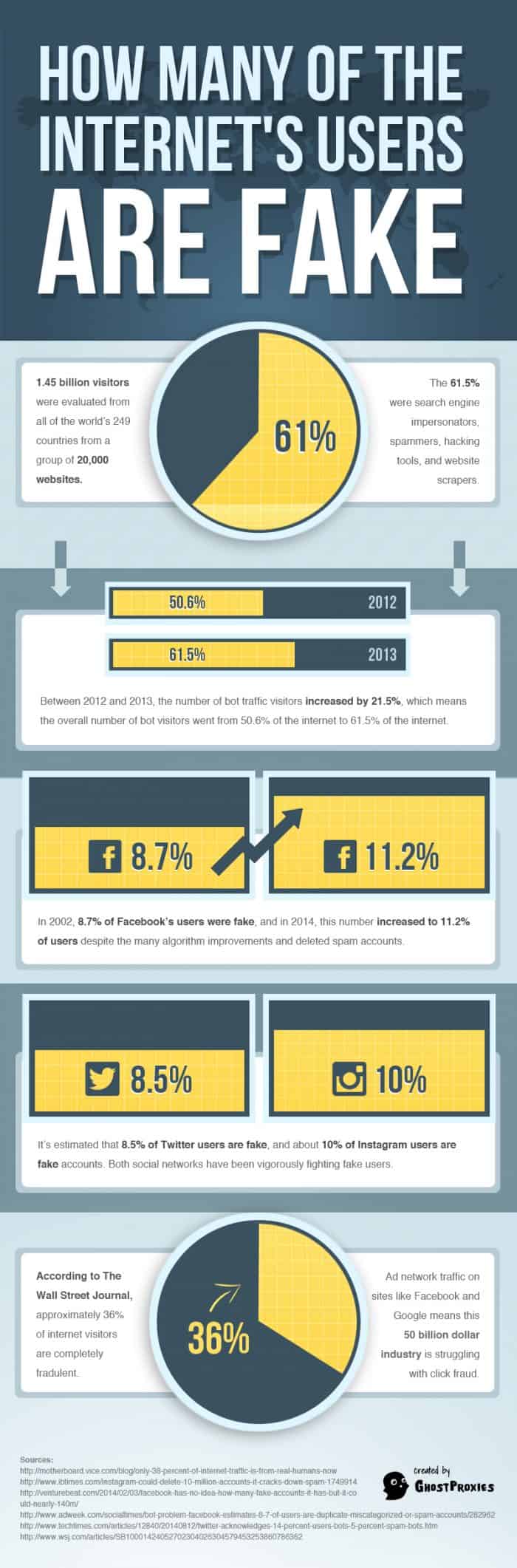 The old metaphor for the Internet was an information superhighway. Real highways have anywhere from two to a half-dozen or so lanes, so you might assume a superhighway has a few more than that. This was back years ago, though, before the web grew to the juggernaut it is today. The modern superhighway might be millions of lanes, all packed with traffic, people going to and fro at high speeds.Can you imagine the traffic problems on such a highway? Billions of cars traveling at any given time, to and from billions of destinations. One bottleneck, one accident, and you have gridlock for lightyears.The problem isn’t helped, either, by the incredible number of these metaphorical cars that don’t have drivers. These cars are the fake traffic that spreads around the Internet, coming from a variety of sources. You have your proxy users, people in other cars remote controlling cars so the metaphorical Internet police don’t locate the driver. You have your spiders, robot cars with Google Earth cameras strapped to the top, taking surveys of the landmarks they pass. You even have the fake people, cardboard cutouts surrounding the skyscrapers that are Facebook, Twitter, Instagram, and the rest. Bots Both Good and Bad The Internet is just packed full of bots of various kinds, fake users riddle social networks and web forums, bots comment on blog posts anywhere they can. Spiders crawl websites to index them or to look for changes. Malicious spiders look for vulnerabilities or opportunities for spam. “Fake” traffic comes from proxy URLs, redirects to hide the source of the traffic for good or ill.That’s really the question, isn’t it? With so much bot traffic flying around and so many fake accounts made, how much of it is valuable? How much of it is dangerous? How much of it do people even realize is going on?Well, we can at least answer the last question. We’ve been hard at work compiling statistics about fake users, proxy traffic and web bots, and we have it here for you in convenient infographic form. Fake Users Fake users on websites are admittedly a problem. Facebook, Twitter, Instagram and all the rest fight to combat them, by increasing detection and removing fake users. They try to make it detrimental to accumulate fake users, but there’s not a lot they can do to fully fix the problem.What about legitimate fake user accounts? Are there ever legitimate uses for them? I can think of a few. For example, you might want a fake account to test how your page looks from a user’s perspective. A Facebook Page Admin, for example, can look at their page, but they still see all of the insights and additional tools available to them. They would need an account without access in order to see how their page truly looks. PHPBB, a forums software, solved this issue by giving admins the ability to view the site from the perspective of any user, so they don’t need to create an account specifically for that purpose.Unfortunately, malicious and spam-centric fake users vastly outnumber the few legitimate uses for sock puppet accounts. It’s for reasons like this that some Asian games and social networks require valid national identity numbers to register. Proxy Traffic Proxy traffic, likewise, can be used for good and ill. Some people use proxies to get around IP blocks on forums and in games, or to make it look like their posts – possibly spam posts – come from a different location so they can’t be blocked easily. Proxies are even used to hide the source of hacks and DDoS attacks.On the other hand, proxy traffic can be useful to test geolocation services, or to get around certain tracking and privacy invasion software. Privacy is a huge issue on the Internet today, Web Crawlers Web spiders, of course, are the bread and butter of many online services. Any search engine either uses their own fleet of web drones, or they borrow their index from another engine that does. It’s not only a legitimate use, it’s a necessary one, if we want such services to remain functional. The Internet is so large and changes so often that it would be impossible to keep up with it in any other way.On the other hand, you also have malicious web crawlers. You have crawlers that ignore search engine directives to index pages that otherwise would remain invisible to the public. You have crawlers that search for comment fields or contact lists to submit their advertising through, which are the front line soldiers in the Captcha wars. You have similar bots designed to create fake accounts on forums, blogs and social networks, for use in creating fake accounts. There are bots that steal content, bots that look for outdated software with known vulnerabilities, and more .No one can say that these malicious bots are anything other than a problem, but there’s no good way to block bot traffic without blocking the beneficial traffic as well, at least not on an Internet-wide basis. Perhaps the first step to a better solution, at least, is an awareness of the scale of the problem.
The old metaphor for the Internet was an information superhighway. Real highways have anywhere from two to a half-dozen or so lanes, so you might assume a superhighway has a few more than that. This was back years ago, though, before the web grew to the juggernaut it is today. The modern superhighway might be millions of lanes, all packed with traffic, people going to and fro at high speeds.Can you imagine the traffic problems on such a highway? Billions of cars traveling at any given time, to and from billions of destinations. One bottleneck, one accident, and you have gridlock for lightyears.The problem isn’t helped, either, by the incredible number of these metaphorical cars that don’t have drivers. These cars are the fake traffic that spreads around the Internet, coming from a variety of sources. You have your proxy users, people in other cars remote controlling cars so the metaphorical Internet police don’t locate the driver. You have your spiders, robot cars with Google Earth cameras strapped to the top, taking surveys of the landmarks they pass. You even have the fake people, cardboard cutouts surrounding the skyscrapers that are Facebook, Twitter, Instagram, and the rest. Bots Both Good and Bad The Internet is just packed full of bots of various kinds, fake users riddle social networks and web forums, bots comment on blog posts anywhere they can. Spiders crawl websites to index them or to look for changes. Malicious spiders look for vulnerabilities or opportunities for spam. “Fake” traffic comes from proxy URLs, redirects to hide the source of the traffic for good or ill.That’s really the question, isn’t it? With so much bot traffic flying around and so many fake accounts made, how much of it is valuable? How much of it is dangerous? How much of it do people even realize is going on?Well, we can at least answer the last question. We’ve been hard at work compiling statistics about fake users, proxy traffic and web bots, and we have it here for you in convenient infographic form. Fake Users Fake users on websites are admittedly a problem. Facebook, Twitter, Instagram and all the rest fight to combat them, by increasing detection and removing fake users. They try to make it detrimental to accumulate fake users, but there’s not a lot they can do to fully fix the problem.What about legitimate fake user accounts? Are there ever legitimate uses for them? I can think of a few. For example, you might want a fake account to test how your page looks from a user’s perspective. A Facebook Page Admin, for example, can look at their page, but they still see all of the insights and additional tools available to them. They would need an account without access in order to see how their page truly looks. PHPBB, a forums software, solved this issue by giving admins the ability to view the site from the perspective of any user, so they don’t need to create an account specifically for that purpose.Unfortunately, malicious and spam-centric fake users vastly outnumber the few legitimate uses for sock puppet accounts. It’s for reasons like this that some Asian games and social networks require valid national identity numbers to register. Proxy Traffic Proxy traffic, likewise, can be used for good and ill. Some people use proxies to get around IP blocks on forums and in games, or to make it look like their posts – possibly spam posts – come from a different location so they can’t be blocked easily. Proxies are even used to hide the source of hacks and DDoS attacks.On the other hand, proxy traffic can be useful to test geolocation services, or to get around certain tracking and privacy invasion software. Privacy is a huge issue on the Internet today, Web Crawlers Web spiders, of course, are the bread and butter of many online services. Any search engine either uses their own fleet of web drones, or they borrow their index from another engine that does. It’s not only a legitimate use, it’s a necessary one, if we want such services to remain functional. The Internet is so large and changes so often that it would be impossible to keep up with it in any other way.On the other hand, you also have malicious web crawlers. You have crawlers that ignore search engine directives to index pages that otherwise would remain invisible to the public. You have crawlers that search for comment fields or contact lists to submit their advertising through, which are the front line soldiers in the Captcha wars. You have similar bots designed to create fake accounts on forums, blogs and social networks, for use in creating fake accounts. There are bots that steal content, bots that look for outdated software with known vulnerabilities, and more .No one can say that these malicious bots are anything other than a problem, but there’s no good way to block bot traffic without blocking the beneficial traffic as well, at least not on an Internet-wide basis. Perhaps the first step to a better solution, at least, is an awareness of the scale of the problem.
